
AVERROES - Whole-Program Analysis Without the Whole Program

Averroes is a tool that generates a placeholder library overapproximating the possible behaviour of the original library. The placeholder library can be constructed quickly without analyzing the whole program (using the separate compilation assumption), and is typically in the order of 80 kB of classes (comparatively, the Java standard library is 25 MB). Any existing whole-program call graph construction framework can use the placeholder library as a replacement for the actual libraries to efficiently construct a sound and precise application call graph.
Downloads
- averroes.jar: a runnable
JAR for Averroes. Averroes requires a properties files named
averroes.propertiesto run. A sample properties file can be found here. More details can be found in this tutorial. Once you have the properties file created, you can run Averroes using the following commands:
$ jar uf averroes.jar averroes.properties
$ java -jar averroes.jar
-
averroes-all.tar.gz: the complete package download for Averroes. It contains all the Java sources and runnable JARs for Averroes, as well as the helper tools that comes with it to view application-only call graphs, conforming to this schema.
-
cginfo.jar: a runnable JAR for the command-line tool
CallGraphInfo. It’s an adaption of the toolCallGraphInfofrom ProBe, that is capable of processing application-only call graphs. -
cgviewer.jar: a runnable JAR for the HTTP viewer
CallGraphView. It’s an adaption of the toolCallGraphViewfrom ProBe, that is capable of processing application-only call graphs.
Workflow
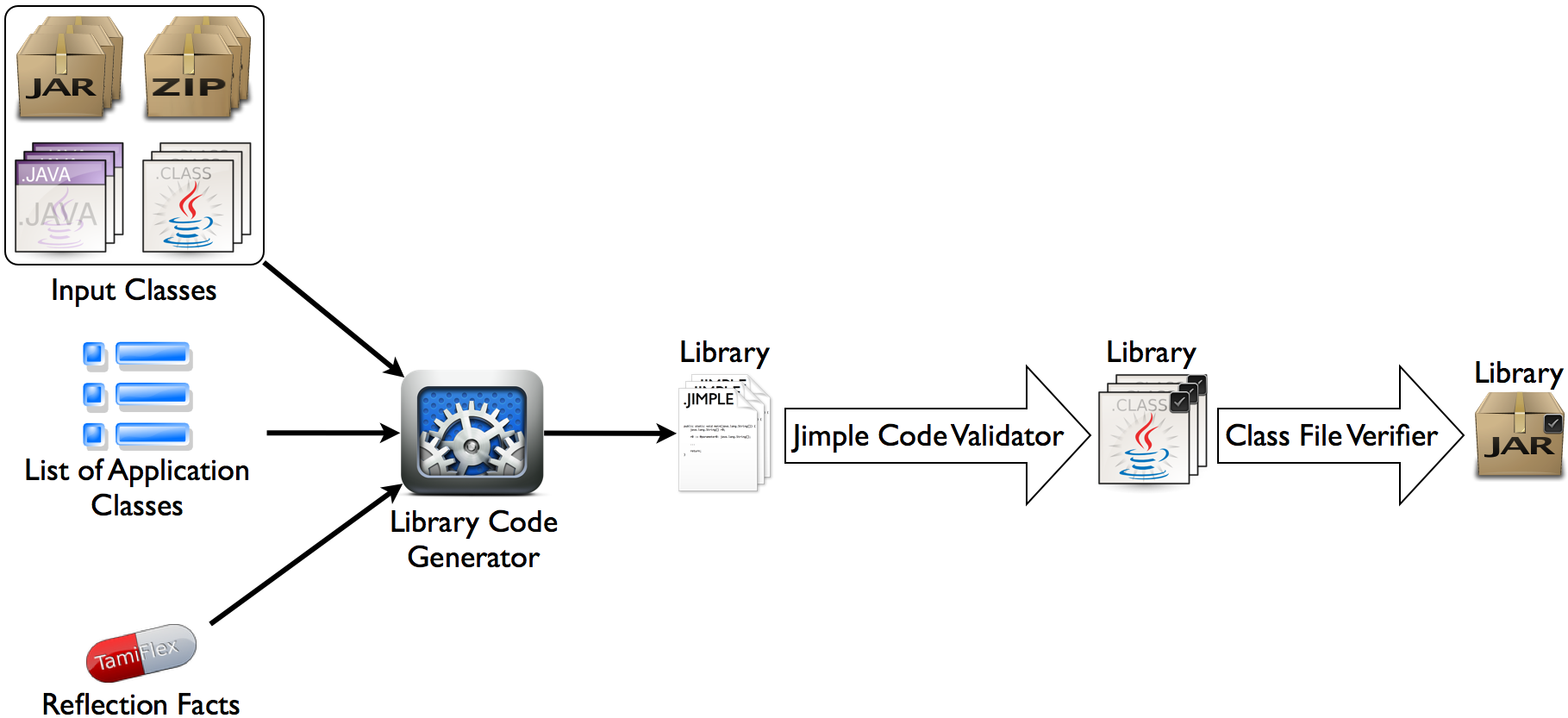
“Hello, World!” Example
We will now step through an example of how to use Averroes to analyze the Java HelloWorld program. First, download the
following file averroes.zip on
your machine, then unzip it. It should unzip to a folder that contains the following files:
- hello.jar: contains the content of the HelloWorld program.
- averroes.jar: this is the Averroes self-contained runnable JAR file.
- rt.jar: the only library dependency for the input application, the JRE JAR file (version 1.4.2_11).
- averroes.properties: a properties file used by Averroes.
- hello.dynamic: a text file that contains any classes the input program loads dynamically. It is empty in this specific example.
- hello.tfx: a text file containing the reflection facts from the output of TamiFlex (which is also empty in this specific example).
Now open the terminal and change to the directory that has the unzipped content of the file you downloaded. To run Averroes, just type in the following command on the terminal:
$ java -jar averroes.jar
Averroes will then output some
statistics about the input JAR files it has processed and the output library is packaged in a file called lib.jar in
the output directory specified in the averroes.properties file. Along with the lib.jar file, there is a classes
directory where all the class files generated by Averroes are located. Note that if you make any changes to the
properties file, you need to run:
$ jar uf averroes.jar averrroes.properties
to update the properties file within the Averroes JAR file to reflect your changes. You can then use the placeholder
library generated by Averroes along with the original application code with any call graph construction framework
(e.g., Spark or Doop) to get the application-only call graph for the HelloWorld program.
Tutorial
A complete step-by-step tutorial on using Averroes to analyze both the DaCapo and the SPEC JVM98 benchmarks can be found here. The output of the experiments we used to empirically evaluate Averroes can be downloaded here. The download contains two folders, one for the DaCapo benchmarks, and one for the SPEC JVM98 benchmarks. Each benchmark program used has a folder that contains the following:
- <benchmark_name>.stats: a text file that contains all the output from the two tools run for each benchmark: SparkAverroes, and DoopAverroes. It contains important information like preprocessing time, analysis time, frequencies of library call-backs, etc.
- <benchmark_name>-gc.stats: a text file that contains the verbose Java garbage collector output. The information in this file is used to evaluate the memory usage of Spark and SparkAverroes.
- callgraph/: a folder that contains all the call graphs generated by the two tools as well as the difference call graphs between them.
- database/: a folder that contains the LogicBlox database used by DoopAverroes after the analysis finishes execution.